Better fail-overs with vmprobe
March, 2016
Hot standbys
Failures happen.
Most companies have learned this the hard way, often at the worst possible moments.
One of the most effective ways to control unreliability is with redundancy. For important systems, companies often maintain 2 or more identically provisioned machines in a hot standby configuration. Under normal operation, one machine called the primary handles all customer traffic. However, if there is a problem with the primary, one of the other machines, called a standby, takes over. This process of switching responsibility from a failing server to a functioning server is known as failing-over.
In addition to emergency situations, fail-overs are often performed during normal operations, for example to switch traffic from a server running an old software version to a server running an upgraded version. Some companies such as Netflix even routinely fail-over production servers to test their failure response!
Filesystem cache
Files that are in use tend to stay in use.
This simple principle enables one of the most effective performance optimizations: The filesystem cache. When a file is accessed, its meta-data and contents are stored in memory (RAM) in the hopes that it will be accessed again soon. If it is, then the file can be quickly read from memory instead of requiring another slow request to a hard-disk or over the network (NFS, S3FS, etc).
In a perfect world, we would be able to keep all the files we are serving in memory at all times. Unfortunately, many data-sets are much too large to fit in memory. And, even if they weren't, buying this much memory might be wasteful — often it is sufficient to keep only the most frequently requested files in memory. If any one file was just as likely to be requested as any other file, then of course this strategy would not work. Luckily, data access patterns very frequently follow a distribution known as the Zipf distribution.
In a Zipf distribution, you have a small number of files that are extremely popular, a moderate number of files that are moderately popular, and a large long-tail of files that are requested very infrequently. Because of this, filesystem caches and their least-recently-used (LRU) policy which keeps popular files cached in memory are very effective tools for optimizing common server work-loads.
Hot and cold caches
When a server is first started, its filesystem cache is empty.
An empty or out-of-date filesystem cache is said to be cold. Only after requests come in does the filesystem cache start to fill up. After a period of time, the filesystem cache will have figured out which files are popular and will persist them in memory so that the majority of requests can be served quickly from the cache without having to fall back to slow hard-drive access. At this point the server's cache is said to be hot.
The problem with fail-overs is that the standby hosts, since they aren't handling traffic, have cold caches. When the fail-over occurs, customers requesting popular files that were previously being served from memory will have a bad experience until the cache is warmed back up.

One suggestion to mitigate this issue is to not use idle standbys, but instead balance traffic evenly between the servers. While this can work in some scenarios, care must be taken. If you have traffic split between multiple servers then it is hard to be certain that the system can handle peak load in the event of a failure. If one of your servers fails and the remaining server is unable to handle the load, then you don't in fact have a fail-over strategy!
vmprobe
You need a truly hot standby.
vmprobe provides a comprehensive solution to this problem with the vmprobe daemon (vmprobed) tool. vmprobed allows you to take snapshots of the filesystem cache on one server, and restore them to another server. If this operation is performed immediately prior to a fail-over, then the traffic is failed-over to a server with an identically hot cache.
Because we can't predict when emergencies will occur, and because the exact make-up of the hot cache changes over time, vmprobed offers a standby feature that lets you continuously copy the state of the filesystem cache from a primary to one or more standbys.

Experiment
Show me the data!
Amazon Web Services has generously provided equipment for Vmprobe to run these and other experiments through their AWS Activate program.
In order to demonstrate vmprobed's functionality discussed above, we setup the following experiment.
2 file servers (r3.xlarge)
- Each has mirrored copy of 1 million 500 KB files for a total of 500 GB on magnetic EBS drives
- Each server has 30.5 GB memory, so it can cache about 60,000 of the files
- The files are served by nginx in a very standard configuration
1 request router (m4.xlarge)
- A simple nginx proxy configured to send all traffic to one file server unless it is inaccessible, in which case it sends to the other
4 clients (m4.large):
- These clients continually request files from the request router
- They are configured to perform 12.5 requests per second each, for a total of 50 requests per second
- The files to request are randomly sampled from a Zipf distribution with an exponent of 1.3, meaning ~97% of requests are for the most-popular 10 GB of files
After letting the cache fill up on the primary file server, its nginx was disabled causing the router to route subsequent traffic to the other file server. This chart shows the resulting request latencies (the red arrow indicates when the fail-over occurred):
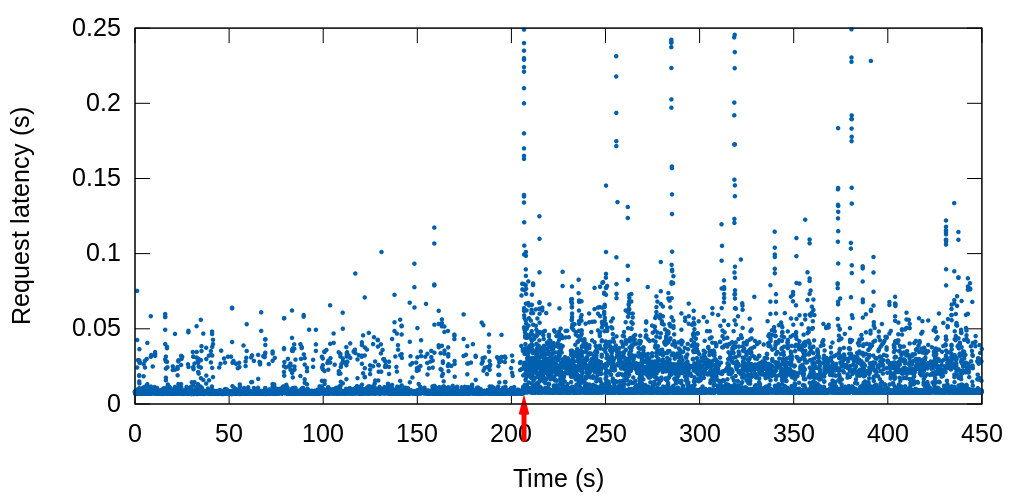
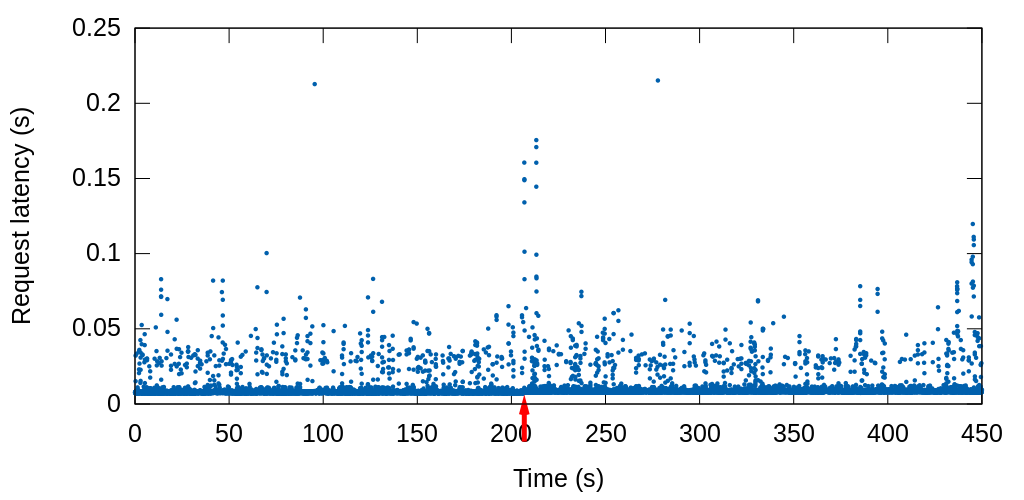
Next, we set the servers up identically except we enabled vmprobed and configured it to copy the filesystem cache state from the primary to the standby.
Here is the resulting fail-over:
FAQ
Are there alternatives to hot-standbys? Can vmprobe help with them?
Yes and yes. Some companies prefer to dynamically scale their infrastructure in response to increasing or decreasing usage patterns. If done carefully, this can also provide the redundancy required for high availability applications. The challenge in these environments is that when introducing a new server into production, the filesystem cache should be warmed appropriately before-hand. vmprobed is great for this use-case as well, since it provides a flexible REST API that is easy to adapt into your application stack.
Is this still an issue with solid-state drives?
Solid-state drives (SSDs) have much lower random seek latency than traditional spinning hard-drives which, if you can afford them, somewhat reduce the necessity of managing the filesystem cache in this scenario. That said, the fundamental issues described in this paper still apply. Memory access is many times faster than SSD access, and has much more predictable latency (especially with EBS). Furthermore, failing-over to a cold server tends to rapidly issue a high amount of IOPs which can cause much higher latency than the baseline, or require you to purchase much more expensive IOP provisioning.
Of course in a file serving scenario such as this experiment, the latency to the client over the internet will often be the largest bottleneck and can often effectively hide SSD latencies from your customers' perspective. vmprobed is much more effective at managing SSDs in certain other scenarios, for example speeding up database queries.
Want to try vmprobe right now? Please see our install documentation!
Interested in beta-testing vmprobe in your company? Please contact us.